
Computer Science (compsci112358)
Python programming and machine learning with a focus on syntax and beginner-friendly implementation.
Nutrition Label
This creator provides hands-on Python tutorials that prioritize functional code execution and syntax over deep theoretical rigor. Viewers can expect clear, live-coding demonstrations for specific projects, though data science methodologies sometimes lack statistical precision.
Strengths
- +
- +
- +
Notes
- !Machine learning guides focus on syntax but sometimes apply incorrect statistical methods to time-series data.
- !Video descriptions often contain Amazon affiliate links for books; check for clear commission disclosures.
Why this score
“Coding A Christmas Tree with Python”
The content delivers exactly what is promised in the title without deviation or clickbait.
Open receiptTrust Breakdown
Mixed / General Lens: Scored with the default trust weighting.
Confidence pending. Based on 9 long-form videos.
These six Trust Core outputs drive the public creator rating. Communication affects discovery ranking separately. Methodology →
Recent Videos

I Coded a Fake Virus in Python in under30 Minutes

Python Predicts the World Cup Winner… and the Result Shocked Me..

I Simulated 10,000 Future SpaceX (SPCX) Stock Prices in python-Here's What I Found

I Tried Using Python to Predict the S&P 500 Stock Price — Here’s What Happened

How to Code a "Fireworks" Graphic in 15 Lines of Python!

What Happens If You Invest $27 Per Day? Python Reveals Everything
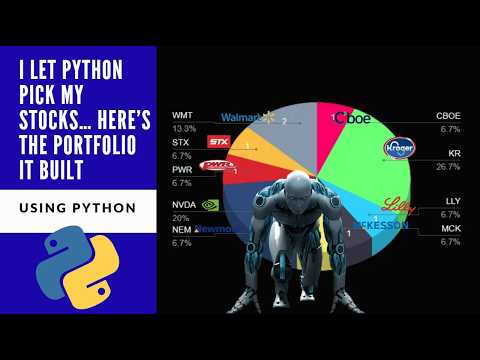
I Let Python Pick My Stocks… Here’s the Portfolio It Built
Flight Price Prediction Using Python and Machine Learning
Predicting Apple Stock Price With 1000 Monte Carlo Simulations
AI Predicts Tesla’s Stock Next Move TSLA Price Forecast Using Prophet (Shocking_Results)

Build A Smart Chat Bot Using Python & Machine Learning Audio Improved

Build a 2025 Federal Tax Calculator in Python (Step-by-Step Tutorial)

Oil Price Shock Simulator Using Python

Build a Simple Stock Trading Strategy with Python (Step-By-Step Tutorial)

Build A Stock/Crypto Fear & Greed Index Scraper in Python Stocks + Crypto
Shareable card
A compact ReReview card and short URL for sharing this trust score.